Tool Details and User Instructions
The robots exclusion protocol (robots.txt) is used by web robots to communicate with a website. The file tells a robot which section of a website to crawl or which section not. Every crawler or robot who is involved in spamming doesn’t respect robots.txt file.
A file uses a protocol named Robots Exclusion Standard. The protocol follows a set of commands that are readable by the bots visiting your website. There are some points to keep in mind:
– If you have disallowed a directory, the bots won’t index or crawl the data unless they find the data from another source on the web.
– The bots interpret syntax differently, for example, if you are setting the user agents in the start like:
User-agent: * Disallow: /
Then there is no need to disallow robots separately again.
– The file is directive only. Some bots may not honor the file.
How to create a robots.txt?
– The file kind of acts like a sitemap to tell the robots which portion to crawl and which not.
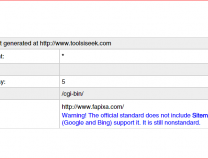
Use our tool to generate robots.txt code for your website and upload the file to your website’s root directory. The robots.txt file should be accessible from “http://www.yourdomain.com/robots.txt”.
What does a normal robots file look like?
A normal or you might say “default” robots.text is like:
User-agent: *
Disallow:
But you can create an advance file with our robots.txt generator.
Advantages of Robots.txt?
1. Low bandwidth usage as you are restricting spiders just to crawl particular sections of a website.
2. People won’t be able to see the stuff when visiting your site via search engines you don’t want them to access.
3. Preventing spam.
How to add a robots.txt file on your website?
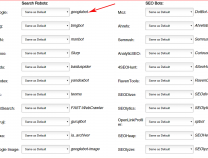
Select options above
Create a text file named “robots.”
Copy the contents of the text area and paste into your text file
Don’t forget to validate your robot code
Add the file to your root directory e-g, https://toolsiseek.com/robots.txt
Also, try our broken link checker tool.
Tool Steps Snapshots